![#Day 1 - What is Kubernetes?[100 Days of Kubernetes]](https://cdn.hashnode.com/res/hashnode/image/upload/v1629918115649/kcqIW36S4.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


Hey guys👋, welcome to my first-ever blog. Do check Anais Urlichs's YouTube channel for the amazing #100DaysofKubernetes video series.
What were the problems with Monolithic architecture?
Initially organizations had and still many organizations have big monolithic architectures for their applications. A 'Monolithic' architecture means that all of the numerous features, components, dependencies, etc are contained within the application package itself. So if we have to modify any existing feature or deploy any new feature in our application we'll have to make sure that, that particular feature doesn't affect the working of some other feature and this, in turn, doesn't affect the working of some feature.
Another big problem was 'Scalability'. Now the term 'Scalability' refers to the idea where an application or a piece of infrastructure can be scaled up(expanded) in real-time to handle the increased load/traffic or scaled down(shrunk) in real-time for decreased load/traffic. Now in our application, if a particular feature is being used more often by more and more users, we'll necessarily have to scale up that feature, but since we are using a monolithic architecture and have defined all the settings and dependencies for our application beforehand, we can never be sure if that feature can be scaled-up within the defined boundaries of the application.
Adding up to the list was the problem of 'Maintainability'. Usually when a developer is making any modifications in the codebase or adding a huge amount of lines of code for a new feature of the application, he/she has to take into consideration, the already humongous amount of code and legacy code because what is perceived as a bug in the codebase can actually be a dependency for a certain line of code and it becomes really difficult to individually abstract layers from the codebase.
Moving from Monolithic to Microservices
To overcome the above-mentioned problems 'containers' came to the rescue, where different features of the same application are packaged in separate containers. These containers are generally 'Docker Containers' but there can be other forms of containers as well. We do this by defining a 'Docker File', which defines a 'Docker Image' that can be further run as a 'Docker Container'.
Why Kubernetes was required?
Imagine an organization that has thousands and thousands of microservices(containers) running that have to be managed. The organization wouldn't want to do this task through scripts as this would be hugely inefficient and a nearly impossible task to do. This is where container orchestration systems came into play and 'Kubernetes' is one of the world's more popular container orchestration systems.
Kubernetes and its architecture
As discussed above, Kubernetes(also known as K8s) is a container orchestration system used for automating the tasks of deploying, scaling, and managing applications. It was open-sourced by Google in 2014.
Let us dive deep into the architecture of a Kubernetes cluster
Suppose you have a Kubernetes cluster that is running on a cloud provider like AWS or GCP, or it is a local Kubernetes cluster running through minikube or microk8s.
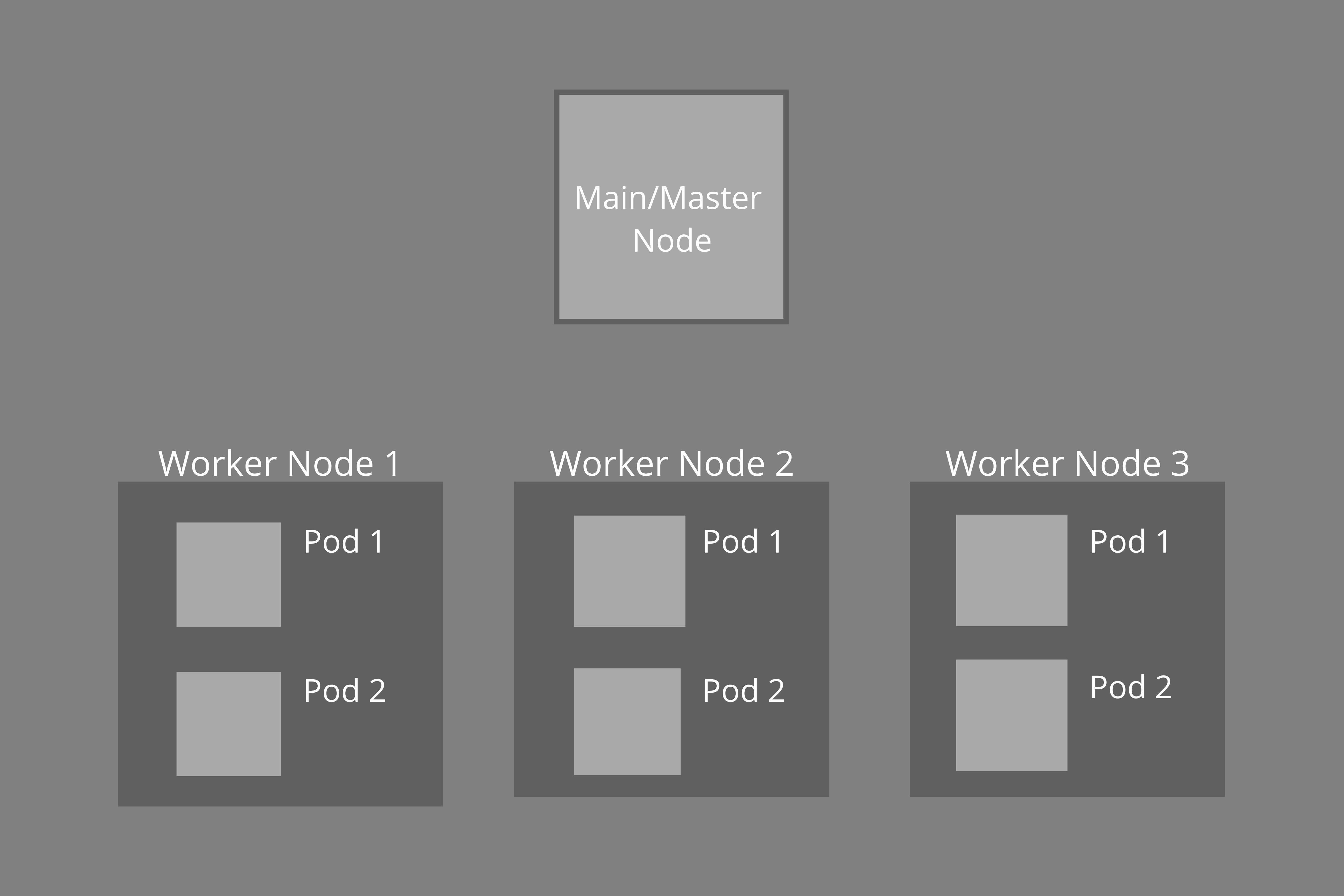
A cluster will usually contain a main or master node and several worker nodes. Each of the worker nodes runs pods within them. There can be multiple pods within a worker node. These pods will run the containers in which our application is packaged but they don't run the actual containers but an abstraction of what that container is supposed to be. Now, these pods will have to communicate with each other in order to work together, and to do so, they use IP addresses. Every time a pod is started, an IP address is assigned to it. Now if a pod goes dead in a node, then we have to find a way to start it up again and connect it with other pods in the cluster using its new IP address. For this task, there are services around a pod in a cluster whose main tasks are first, to provide IP address to the pod and second, to provide a load balancer(this will be covered in future blogs).
The Main or Master Node

The Master Node has basically four components -
API Server - It exposes the Kubernetes API which allows the user to communicate with the Kubernetes cluster through the command line.
Controller Manager - It keeps track of the state within the cluster. For example, it checks and acts upon if any nodes go down, creates pods to run one-off tasks, is responsible for connecting services with the pods, etc.
Scheduler - Basically keeps track of newly created pods with no assigned nodes and assigns them the same.
etcd - Acts a primary datastore of Kubernetes backing all the cluster data, keeps track of the state changes within the cluster.
Lastly, we usually use YAML syntax to interact with our clusters in Kubernetes.